
[자료구조 with C언어] 큐 (Queue)

INDEX
| 01. 큐(Queue)란? |
| 02. 원리 |
| 03. 구현 |
01. 큐(Queue)란?
큐(Queue)는 먼저 들어온 데이터를 먼저 처리하는
선입선출(First-in-First-out, FIFO) 구조입니다.

이때 구조는 위 아래가 뚫려있는 원통형 구조로 생겼고,
위에서 데이터를 넣었을 때 먼저 넣은 데이터부터
아래로 꺼낼 수 있습니다.

큐가 실제로 응용되고 있는 대표적인 분야는
은행 번호표입니다.
버튼을 누르면 큐 구조에 해당하는 번호가 삽입이 되고,
순차적으로 먼저 들어간 번호부터 처리되어
창구에서 번호가 호출되게 됩니다.

또한 프린터 드라이버도 마찬가지입니다.
동시에 여러 장의 문서를 출력하게 되면
프린터기는 동시에 여러 장을 출력할 수가 없기 때문에
위 사진처럼 대기열이 걸리게 됩니다.
이때, 먼저 들어온 프린트 명령부터 순차적으로 처리합니다.
뿐만 아니라 수강 신청 대기열도 큐 구조를 활용한 예시로 들 수 있습니다.
먼저 들어온 데이터를 순차적으로 처리해야 되는
다양한 상황에 활용할 수 있는 것이 큐 구조입니다.
02. 원리
큐(Queue)는 크게
데이터를 넣는 것과 빼는 것
두 가지 동작으로 구분됩니다.
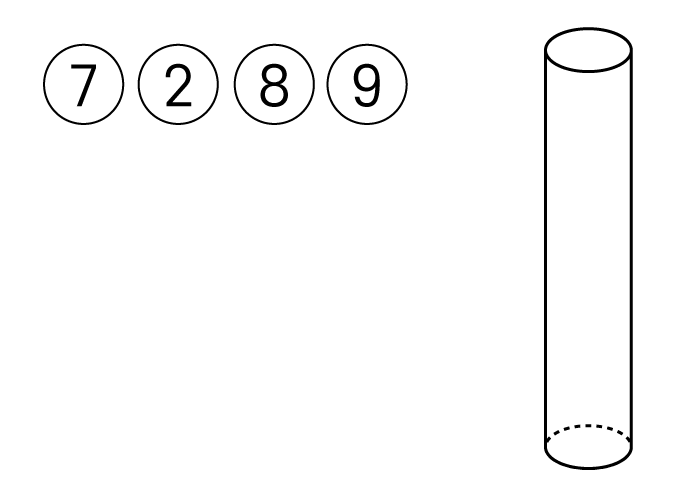
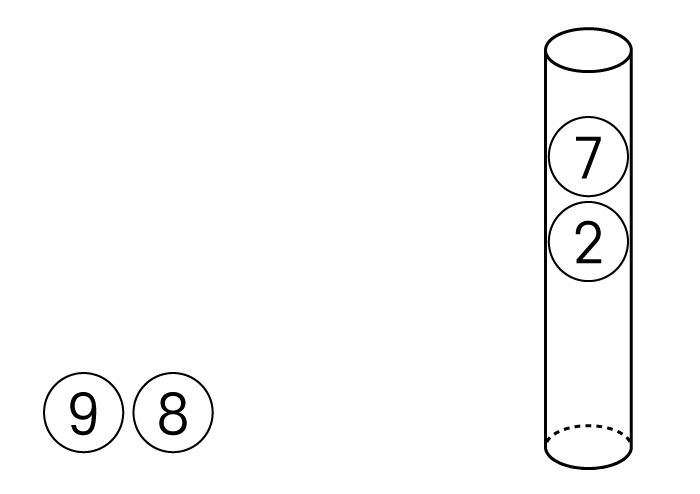
위 아래가 뚫린 원통과 7,2,8,9의 데이터가 있습니다.
이때, 9와 8을 순서대로 넣게되면
아래와 같은 상태가 됩니다.
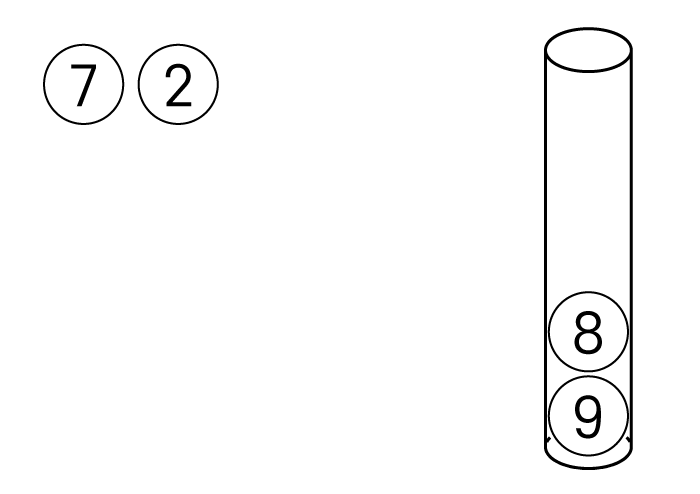
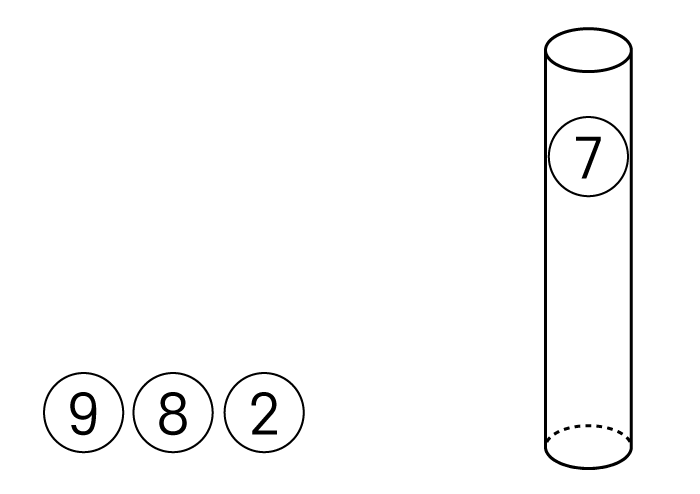
이번엔 원통에서 데이터를 꺼내보게된다면
아래와 같은 상태가 됩니다.
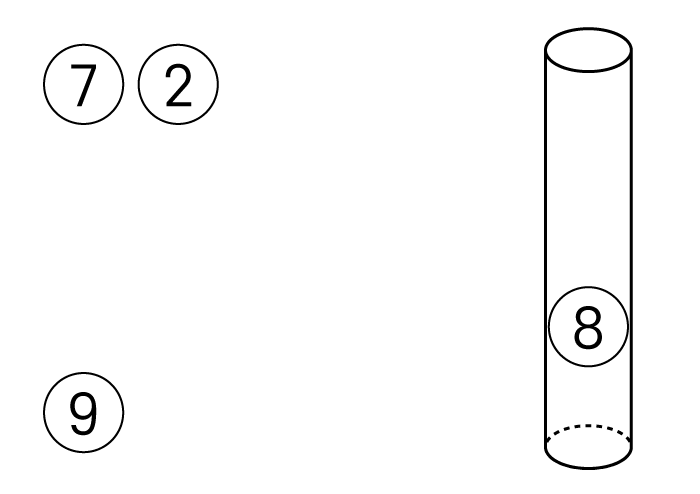
남은 데이터 7, 2를 순서대로 원통에 넣으면
아래와 같은 상태가 됩니다.
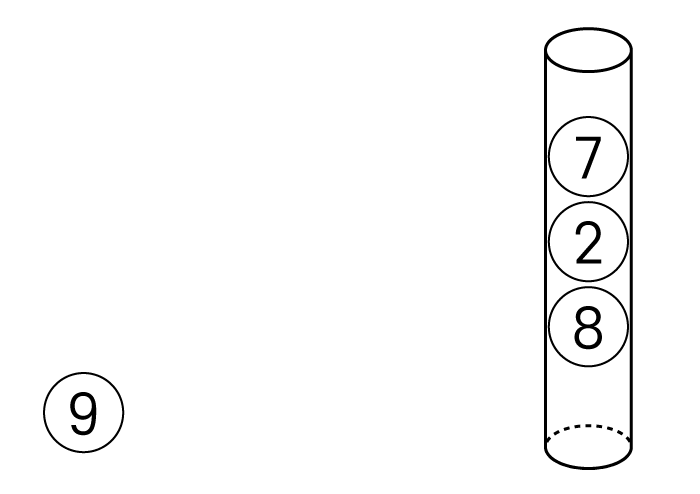
원통의 데이터를 다시 두 번 꺼내면
아래와 같은 상태가 됩니다.
이처럼 큐 구조도
먼저 들어온 데이터를 먼저 꺼내는 방식을 통해
작동되는 구조입니다.
03. 구현
큐(Queue)는 추상자료형으로 분류되기 때문에
정석으로 구현하려면 연결리스트를 활용해야 합니다.

하지만 C언어에서는 구현의 편의를 위해
배열을 활용하여 구현하는 것이 일반적입니다.
int Queue[100];
int Front=-1,Rear=-1;Front는 항상 Queue의 가장 첫 번째 데이터의 index를 가집니다.
Rear는 항상 Queue의 가장 마지막 데이터의 index를 가집니다.
따라서 Rear를 통해서는 데이터를 삽입하고,
Front를 통해서는 데이터를 꺼낼 수 있습니다.
구현에 있어 주의할 점은
Queue는 Front와 Rear를 통해서만 접근이 가능한
제한적으로 접근 가능한 구조라는 것입니다.
아래는 큐의 대표적인 연산입니다.
| push(data) | data를 Queue의 가장 위에 삽입 |
| pop() | Queue의 가장 아래의 data를 제거 |
| front() | Queue의 가장 아래의 data를 반환 |
| size() | Queue에 들어있는 data 수를 반환 |
| empty() | Queue가 비어있으면 true(1), 그렇지 않으면 false(0) 반환 |
void push(int data)
{
Queue[++Rear] = data;
}
void pop()
{
Front++;
}
int front()
{
return Queue[Front+1];
}
int size()
{
return Rear-Front;
}
int empty()
{
return Front==Rear ? 1:0;
}
printf("9를 삽입\n");
push(9);
printf("8을 삽입\n");
push(8);
printf("현재 큐 사이즈 : %d\n",size());
if(empty()) printf("큐가 비었습니다.\n");
else printf("큐에 데이터가 존재합니다.\n");
printf("front 데이터 : %d\n",front());
printf("큐 데이터 제거\n");
pop();
printf("현재 큐 사이즈 : %d\n",size());
printf("front 데이터 : %d\n",front());
printf("front 데이터 제거\n");
pop();
if(empty()) printf("큐가 비었습니다.\n");
else printf("큐에 데이터가 존재합니다.\n");
printf("2를 삽입\n");
push(2);
printf("7을 삽입\n");
push(7);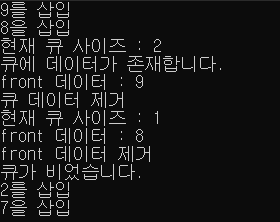
9와 8을 순서대로 삽입하면
큐의 상태가 아래와 같이 변합니다.
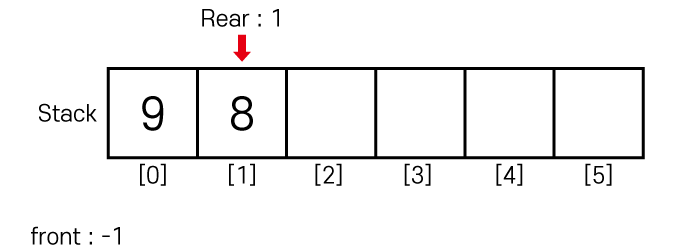
Rear를 통해 삽입 연산을 수행하기 때문에 Rear는 1이 되고,
큐의 사이즈는 Rear - Front 즉, 2가 됩니다.
또한 Front와 Rear가 다르기 때문에
큐에 데이터가 존재한다는 것을 알 수 있습니다.
현재 가장 먼저 처리될 데이터는
큐의 Front+1번 째 데이터인 9입니다.
이때 pop() 연산을 수행하게되면
큐의 상태는 아래와 같이 변합니다.
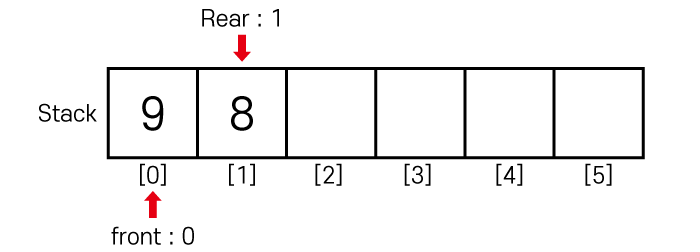
Front 값만 1 증가한 것이기 때문에
위 처럼 실제로 배열에서 데이터가 삭제되지는 않습니다.
하지만 큐 구조는 Front와 Rear를 통해서만
제한적으로 접근이 가능한 구조이기 때문에
9는 삭제된 것과 다름없습니다.
이때 큐의 사이즈는 Rear - Front, 즉 1입니다.
큐의 Front + 1번 째 데이터는 8이고,
한번 더 pop() 연산을 수행하면
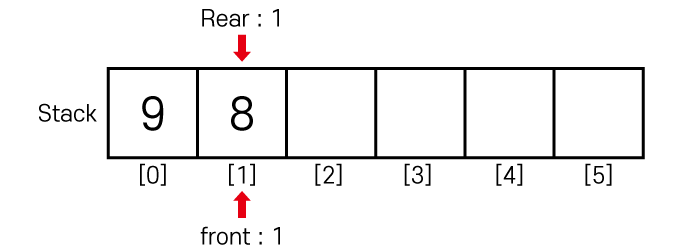
Front는 1이 됩니다.
또한 Rear와 Front가 같아졌기때문에
큐가 비어있는 것을 확인 알 수 있습니다.
이번에는 2와 7을 순서대로 삽입 하게 되면
큐의 상태는 아래와 같이 변하게 됩니다.
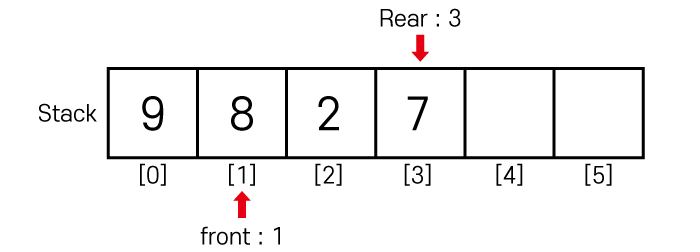

여기까지만 보면 한 가지 문제가 발생함을 확인할 수 있습니다.
Rear와 Front는 각자 증가 연산만 수행할 수 있기 때문에
이전에 한번 사용했던 배열의 index는 재활용이 불가능하게 됩니다.
따라서 삽입 삭제 연산을 많이 수행해야 된다면
이러한 방식은 오버플로우 오류를 유발할 수 있습니다.
이러한 문제를 해결하기 위해서는
두 가지의 방법이 있습니다.
첫 번째 방법은
큐를 정석대로 연결리스트를 통해 구현하는 것 입니다.
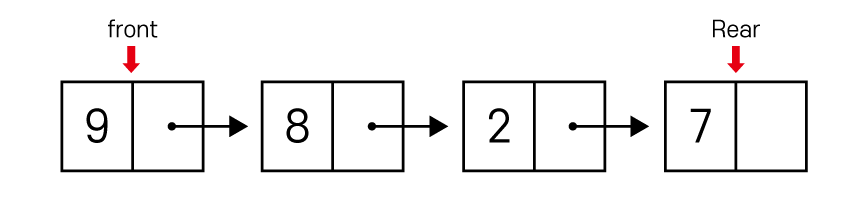
추상적인 동적할당으로 구현되기 때문에
노드가 계속해서 삽입 삭제되어도 상관이 없습니다.
일반적인 연결리스트의 구현 방식대로
구현할 수 있습니다.
두 번 째 방법은
원형 큐를 만드는 것 입니다.
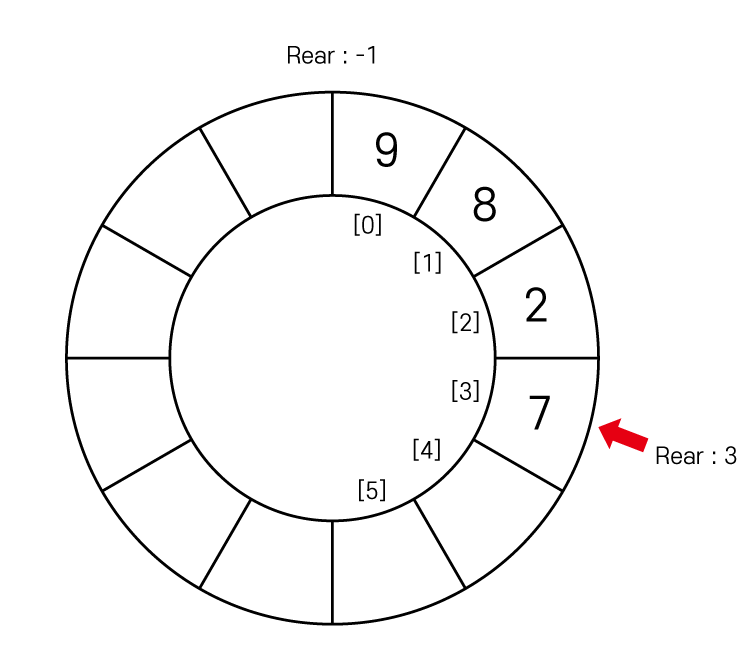
그림으로 표현하면 이렇게 표현되지만
보기와는 달리 배열로 구현할 수 있습니다.
원형으로 큐를 구현하게 된다면
Rear와 Front가 계속해서 큐를 뱅글 뱅글 돌기 때문에
사용했던 index라도 재활용이 가능해집니다.
구현하는 방법은
Rear나 Front가 마지막 방에 도달하게 되면
다시 0으로 초기화를 해주는 방식으로 구현할 수 있습니다.
void push(int data)
{
Queue[(++Rear)%100] = data;
}
int front()
{
return Queue[(Front+1)%100];
}이렇게 큐의 사이즈 만큼 mod 연산을 통해
구현이 가능합니다.
큐 구조는 선입 선출이 필요한 다양한 문제에서
활용할 수 있는 주요 자료구조 중 하나입니다.
아래의 문제를 풀어보면
큐 구조에 대해서 잘 이해할 수 있습니다.
10845번: 큐
첫째 줄에 주어지는 명령의 수 N (1 ≤ N ≤ 10,000)이 주어진다. 둘째 줄부터 N개의 줄에는 명령이 하나씩 주어진다. 주어지는 정수는 1보다 크거나 같고, 100,000보다 작거나 같다. 문제에 나와있지
www.acmicpc.net
'프로그래밍 > 자료구조 \ 알고리즘' 카테고리의 다른 글
| [자료구조 with C언어] 스택 (Stack) (2) | 2022.10.04 |
|---|---|
| [자료구조 with C언어] 연결리스트 (Linked List) (0) | 2022.09.03 |

