
[자료구조 with C언어] 연결리스트 (Linked List)

INDEX
| 01. 연결리스트란? |
| 02. 원리 |
| 03. 구현 |
01. 연결리스트란?
연결리스트란,
일반적으로 사용하는 배열과 달리
동적으로 각 칸들이 앞, 뒤로 사슬처럼 연결되어 있는 자료구조


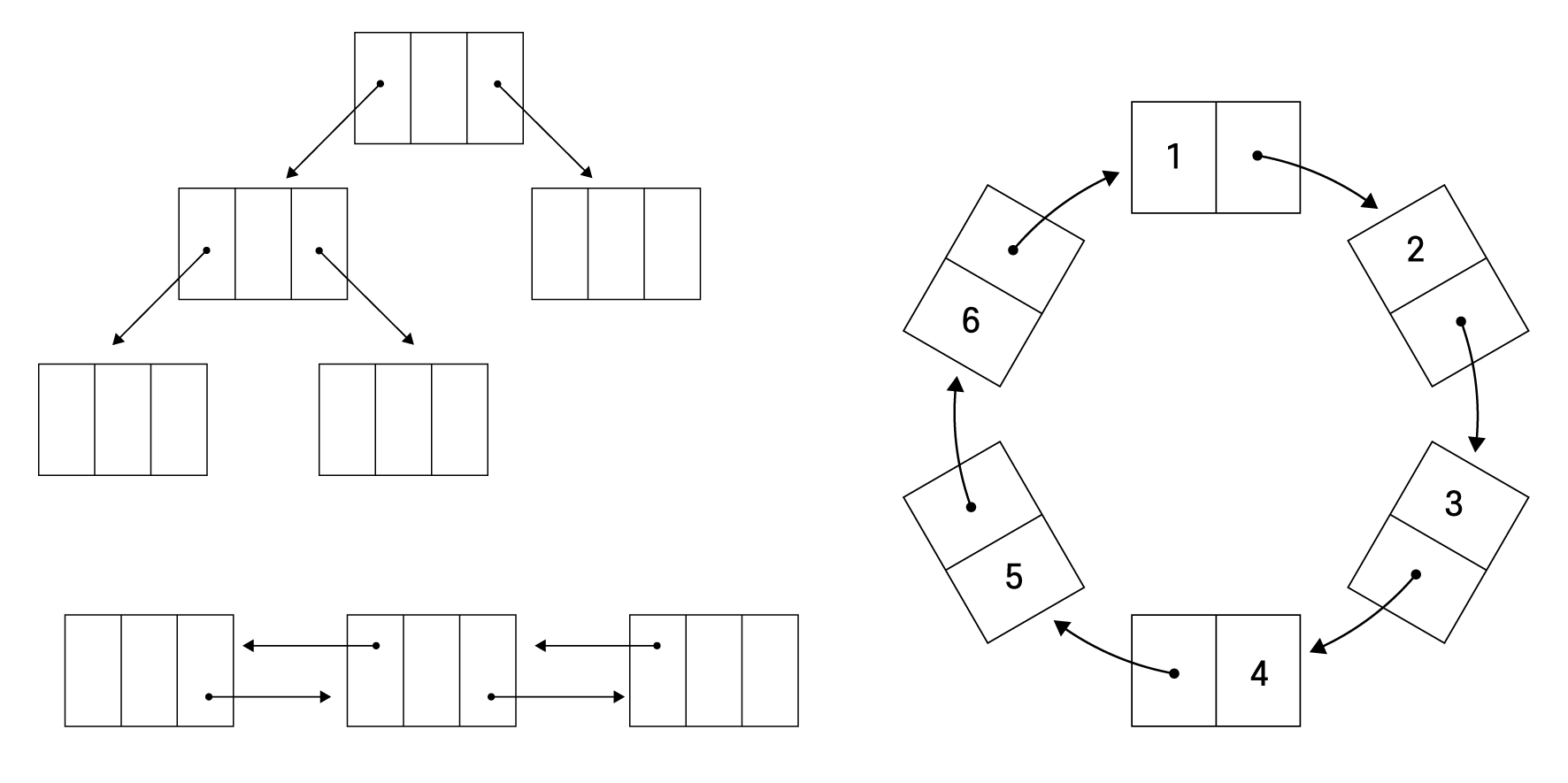
위 사진처럼 연결리스트는
앞, 뒤가 포인터를 통해 사슬처럼 연결되어 있는 구조입니다.
각 칸은 동적으로 할당되며, data와 주소값을 동시에 저장할 수 있어야하기 때문에
구조체로 만들 수 있습니다.
"배열보다 만들기도 어려운데 연결리스트를 왜 쓰죠?"
라고 생각할 수 있습니다.
연결리스트는 아래와 같은 이유로 사용됩니다.
1. 칸 자체를 삭제할 수 있다.

배열에서는 칸 자체를 삭제할 수는 없습니다.
따라서 해당 데이터가 삭제되었다는 '표시'를 대신해서 남겨둡니다.
예를 들어,
위 예시처럼 배열에서 5를 삭제하고 싶다면
5대신 0을 해당 칸에 대입하여 삭제되었다는 '표시'를 남기는 것입니다.
배열에서는 이처럼 데이터를 삭제할 수는 있지만
데이터가 들어있던 칸을 삭제할 수는 없습니다.

반면 연결리스트의 각 칸들은 동적으로 구현되고,
포인터를 통해 다음 칸의 주소를 저장하는 방식으로 연결된 구조이기 때문에
각 칸들은 원하는 대로 삭제가 가능합니다.
예를 들어,
위 예시에서 5가 저장된 칸을 삭제하려면
1이 저장된 칸의 포인터를 10이 저장된 칸의 주소로 바꾸고
5가 저장된 칸은 삭제 free() 해버리면 됩니다.
2. 원하는 형태대로 리스트를 구현할 수 있고, 다양하게 활용할 수 있다.
연결리스트 구조를 응용하여
다양한 형태로 구현할 수 있습니다.
맨 앞과 맨 뒤가 연결되어 있는 원형 연결리스트,
포인터가 다음 칸 뿐만 아니라 이전 칸의 주소 값도 저장하는 양방향 연결리스트,
트리형 연결리스트 등
다양한 구조로 응용할 수 있습니다.
02. 원리
연결리스트에서 각 칸은 노드(Node)라고 부릅니다.
그리고 노드는 아래와 같이 구조체를 통해 구현합니다.
struct node
{
int data; // 데이터가 저장되는 공간, 저장할 데이터에 따라 자료형이 달라짐
struct node *next; // 다음 노드의 주소를 저장할 포인터
};
typedef struct node Node; // 구현의 편의를 위해 자료형 이름 재정의 ( struct node → Node )데이터를 저장하는 멤버(data)의 경우
연결리스트에 저장할 자료형에 따라 달라질 수 있습니다.
이렇게 선언한 구조체를 통해 연결리스트를 만들 수 있습니다.
#include<stdio.h>
struct node
{
int data;
struct node *next;
};
typedef struct node Node;
int main()
{
Node a, b, c, d;
a.data = 1;
a.next = &b;
b.data = 2;
b.next = &c;
c.data = 3;
c.next = &d;
d.data = 4;
d.next = NULL;
return 0;
}
위 코드는 정적으로 구현된 연결리스트입니다.
A, B, C, D 는 Node 자료형으로 선언되어 각각 data와 next를 멤버로 가집니다.
data는 저장하고자하는 데이터를 저장할 수 있는 멤버이고,
next는 다음 노드의 주소 값을 저장함으로써 노드의 앞, 뒤를 연결해줄 수 있습니다.
기본적으로 이런 원리와 구조로 연결리스트가 만들어지지만
노드를 원하는 만큼 생성하고 삭제할 수 있어야 하기 때문에
연결리스트는 동적으로 만들어져야합니다.
03. 구현
#include<stdio.h>
#include<stdlib.h>
typedef struct node_
{
int data;
struct node_ *next;
} Node;
Node *head = NULL;
Node *tail = NULL;
int main()
{
while(1)
{
int input;
printf("연결할 데이터를 입력하세요. ");
scanf("%d",&input);
if(input <=0 ) break;
Node *newnode = (Node*)malloc(sizeof(Node));
newnode->data = input;
newnode->next = NULL;
if(head == NULL) head = newnode;
else tail->next = newnode;
tail = newnode;
}
printf("연결리스트 현재 상태 : ");
Node *cur = head;
while(cur != NULL)
{
printf("%d ",cur->data);
cur = cur->next;
}
puts("");
while(1)
{
int k;
printf("삭제할 데이터를 입력하세요. ");
scanf("%d",&k);
if(k <= 0) break;
int search = 0;
Node *cur_prev = NULL;
cur = head;
while(cur != NULL)
{
if(cur->data == k)
{
search = 1;
break;
}
cur_prev = cur;
cur = cur->next;
}
if(search == 1)
{
printf("%d를 삭제합니다.\n",k);
if(cur == head) head = cur->next;
else cur_prev->next = cur->next;
free(cur);
}
else
{
printf("%d를 찾을 수 없습니다.\n",k);
}
}
printf("(삭제 후) 연결리스트 현재 상태 : ");
cur = head;
while(cur != NULL)
{
printf("%d ",cur->data);
cur = cur->next;
}
puts("");
}
위 코드는 동적으로 구현된 연결리스트입니다.
newnode라는 구조체 포인터와 malloc함수를 통해 노드를 계속 생성할 수 있습니다.
Node *head = NULL; // 첫 번째 노드의 주소 저장
Node *tail = NULL; // 마지막 노드의 주소 저장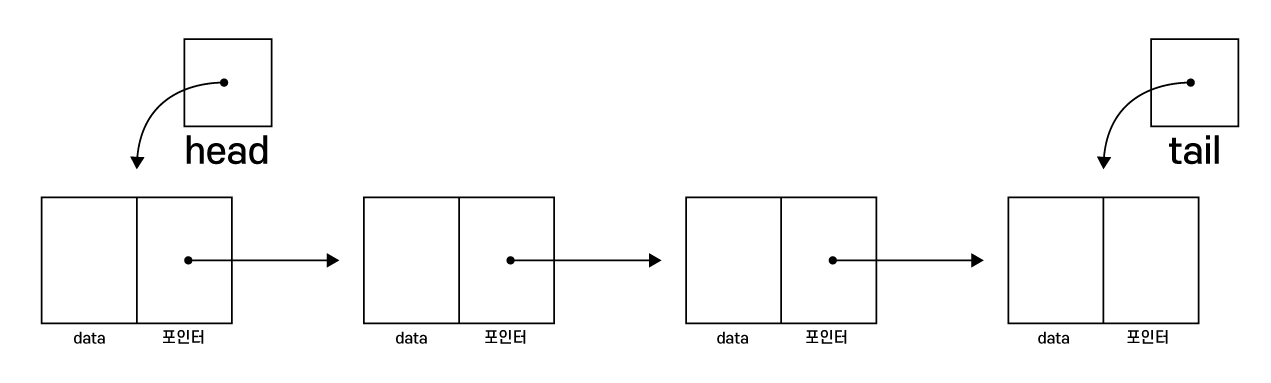
head와 tail은 각각 항상 첫 번째 노드와
마지막 노드의 주소를 항상 저장하는 포인터입니다.
head ?
head가 없다면 연결리스트를 읽을 수 없습니다.
왜냐하면 각 노드가 동적으로 구현되어 있어 각 노드는 주소로만 접근이 가능한 상태입니다.
각 노드는 다음 노드의 주소만을 기억하기에 이전 노드의 주소를 알 수 있는 방법이 없습니다.
따라서 head의 존재는 연결리스트를 첫 번째 노드부터 읽기 위해 반드시 필요합니다.
tail ?
tail은 연결리스트의 새로 생성된 노드를 연결시켜주기 위해 필요합니다.
일반적인 연결리스트 노드 생성 방식은 새로 생성된 노드를 마지막 노드 뒤에 연결하는 방식입니다.
이때, 마지막 노드의 주소값을 tail에 저장하여 방금 새로 생성된 노드와 연결해줄 수 있습니다.
< 노드 생성 과정 >
while(1)
{
int input;
printf("연결할 데이터를 입력하세요. ");
scanf("%d",&input);
if(input <=0 ) break; // 입력 데이터가 0또는 음수면 종료
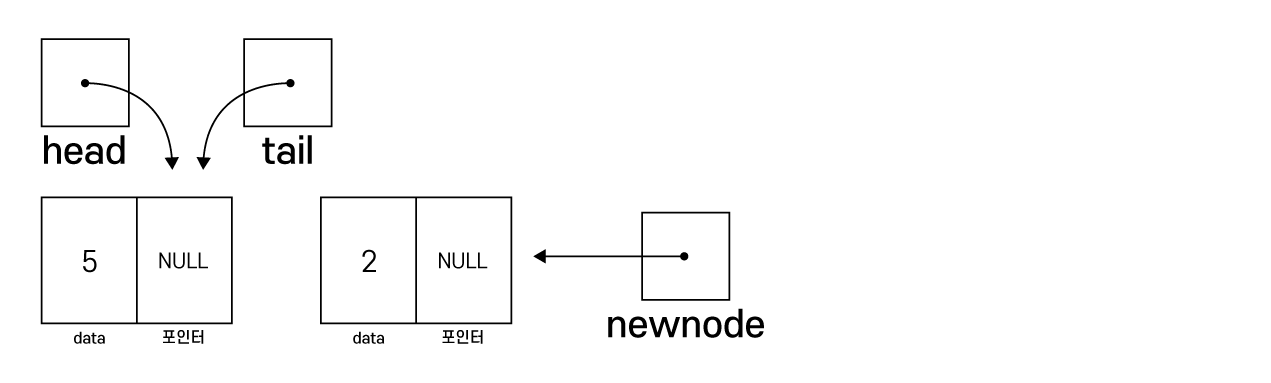
Node *newnode = (Node*)malloc(sizeof(Node)); // 노드 동적 생성
newnode->data = input; // 노드의 데이터 삽입
newnode->next = NULL; // 새로 생성된 노드는 항상 마지막 노드이므로 next는 없음
if(head == NULL) head = newnode; // head가 NULL이면 현재 연결리스트에 노드가 없다는 뜻
else tail->next = newnode; // 마지막에 생성했던 노드의 다음 노드를 방금 생성한 노드와 연결
tail = newnode; // 방금 생성한 노드가 마지막 노드이므로 tail 변경
}

head가 NULL이므로 현재 노드가 없다는 뜻.
즉, 생성한 newnode가 첫 번째 노드이므로 head로 변경, tail도 newnode로 변경
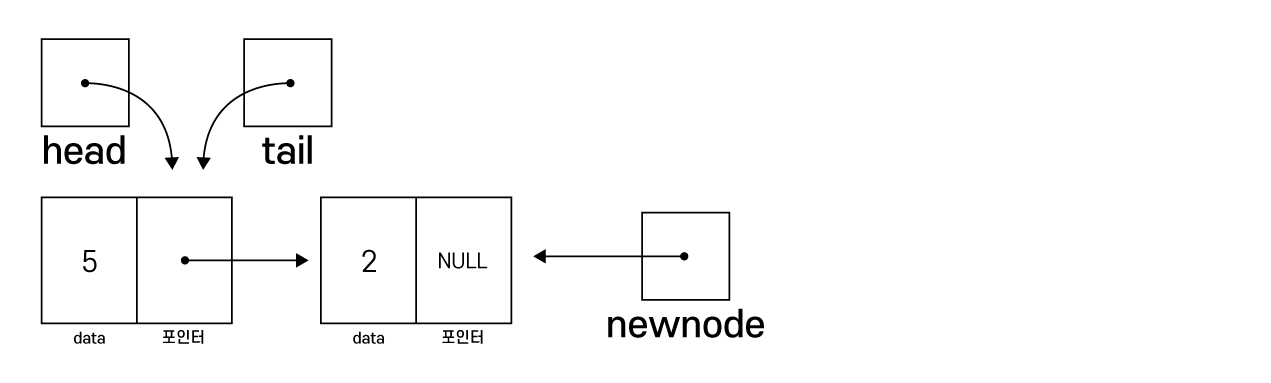
head가 NULL이 아니므로 tail(마지막 노드)의 next를 방금 newnode(방금 생성한 노드)와 연결
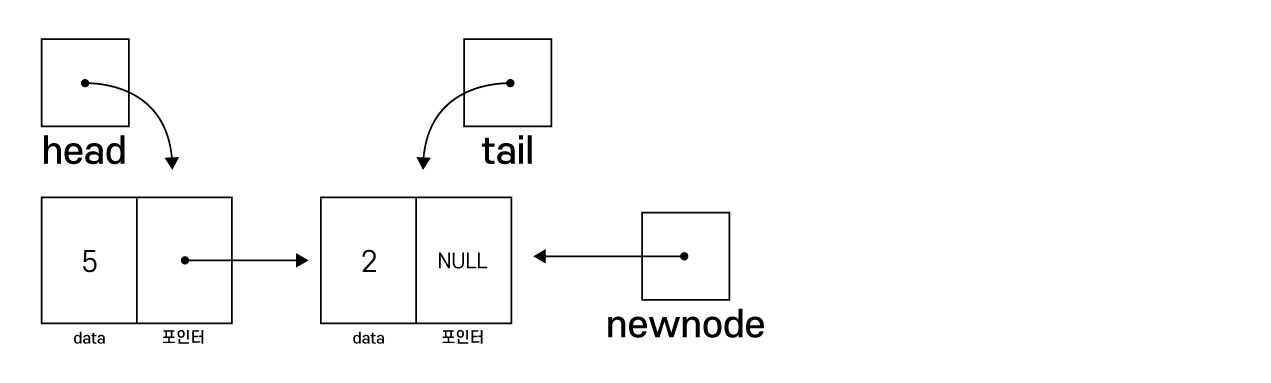
tail을 방금 생성한 노드(newnode)로 변경
(항상 새로 생성한 노드가 마지막 노드가 됨)
~ 반복 ~
< 노드 탐색 과정 >
연결리스트의 노드를 탐색하는 용도로 cur 포인터를 사용합니다.
printf("연결리스트 현재 상태 : ");
Node *cur = head; // 첫 번째 노드(head)부터 연결리스트 탐색
while(cur != NULL) // 더 이상 탐색할 노드가 없을 때 까지 반복
{
printf("%d ",cur->data);
cur = cur->next; // 연결된 다음 노드로 이동
}
puts("");cur은 head부터 시작하여 마지막 노드까지
next 멤버를 통해 다음 노드로 이동하며 연결리스트를 탐색합니다.
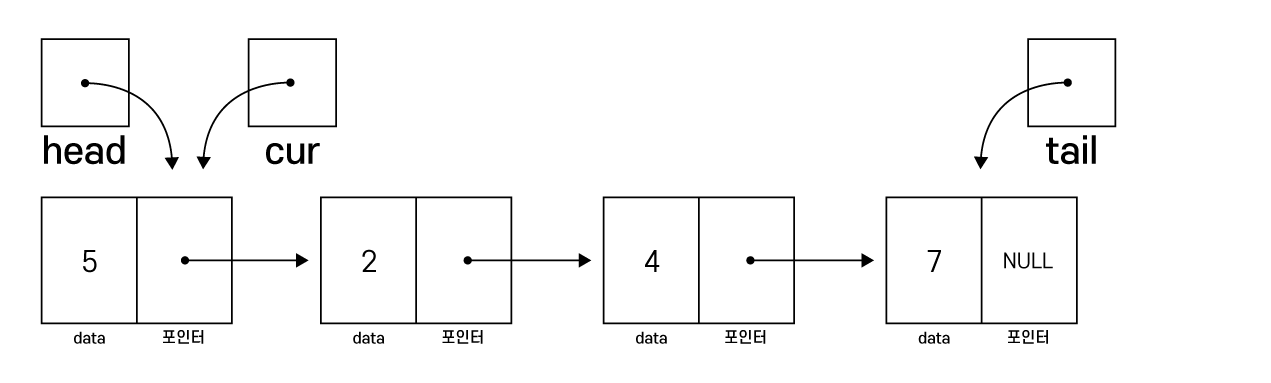
cur 포인터의 초기값은 head입니다.
(head는 항상 연결리스트의 첫 번째 노드의 주소 값)
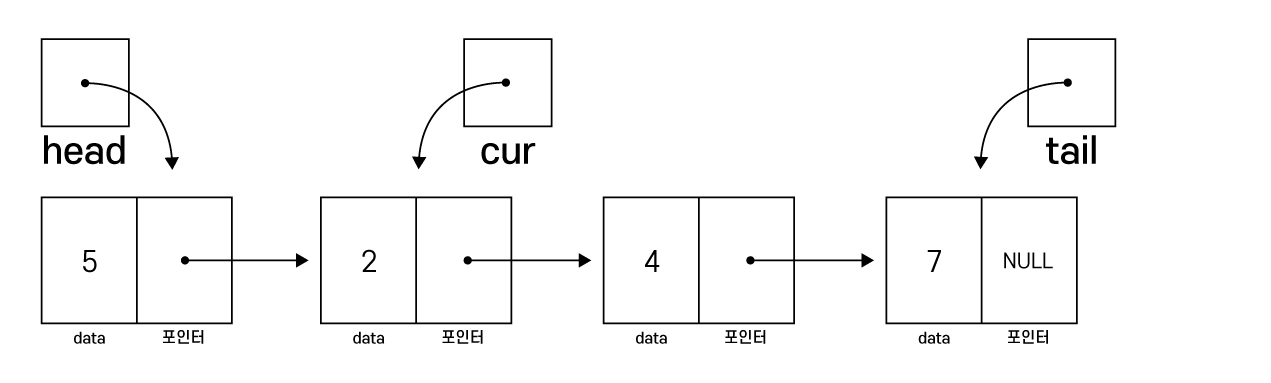
cur = cur->next
3. cur이 tail이 되거나 원하는 데이터를 찾으면 탐색 종료
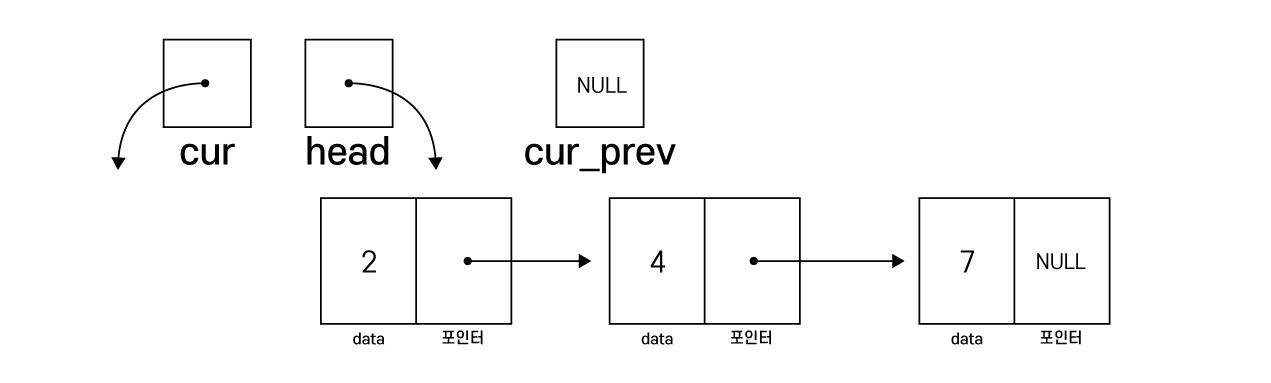
< 노드 삭제 과정 >
while(1)
{
int k;
printf("삭제할 데이터를 입력하세요. ");
scanf("%d",&k);
if(k <= 0) break; // 입력한 데이터가 음수거나 0이면 삭제 종료
int search = 0; // 검색 여부 검사(1이면 있다, 0이면 없다)
Node *cur_prev = NULL; // cur을 뒤 따라 다니는 포인터
cur = head; // 첫 번째 노드(head)부터 연결리스트 탐색
while(cur != NULL) // 더 이상 탐색할 노드가 없을 때 까지 반복
{
if(cur->data == k) // 입력한 데이터를 연결리스트에서 찾았음
{
search = 1; // 찾았으므로 search 변수를 1로 변경
break; // 찾았으므로 탐색 종료
}
cur_prev = cur; // cur의 뒤를 따라 다님
cur = cur->next; // 연결된 다음 노드로 이동
}
if(search == 1) // 삭제할 노드를 찾았을 때
{
printf("%d를 삭제합니다.\n",k);
if(cur == head) head = cur->next; // 삭제할 노드가 head면 head를 이동
else cur_prev->next = cur->next; // 삭제할 노드의 이전 노드와 다음 노드를 연결
free(cur); // cur 삭제
}
else // 삭제할 노드를 찾지 못했을 때
{
printf("%d를 찾을 수 없습니다.\n",k);
}
}삭제하고자 하는 노드를 cur 포인터를 통해 검색하여 해당 노드를 삭제하는 코드입니다.
이때, cur을 뒤 따라가는 포인터인 cur_prev가 존재합니다.
cur_prev는 cur 노드 삭제를 위해 필요한데,
cur을 삭제하면 cur의 이전 노드와 cur의 다음 노드를 새로 연결해주어야 합니다.
하지만 cur을 기준으로 다음 노드는 next 멤버를 통해 접근이 가능하지만
이전 노드는 접근이 불가능 합니다.
따라서 cur의 뒤 노드를 따라오는 cur_prev를 통해 이전 노드에 접근해야 합니다.
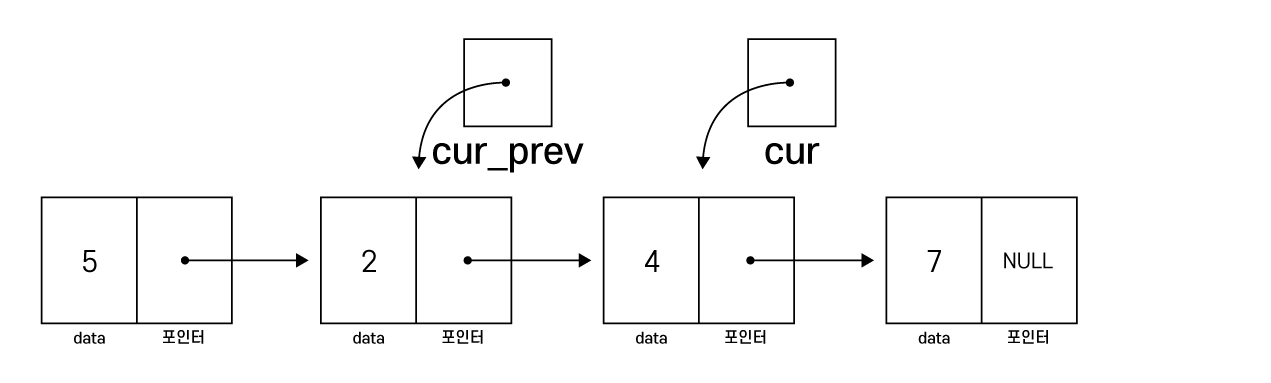
연결리스트를 탐색하여 삭제할 노드를 검색
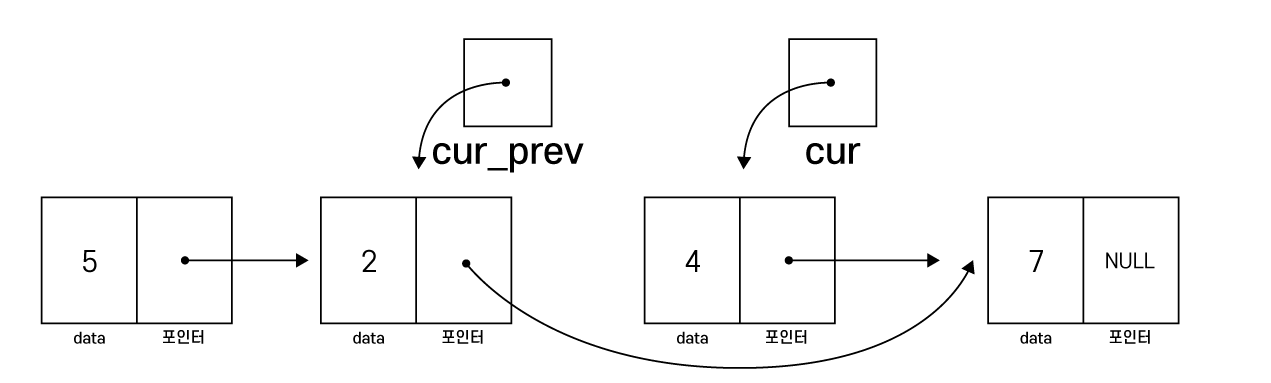
cur_prev->next = cur->next;
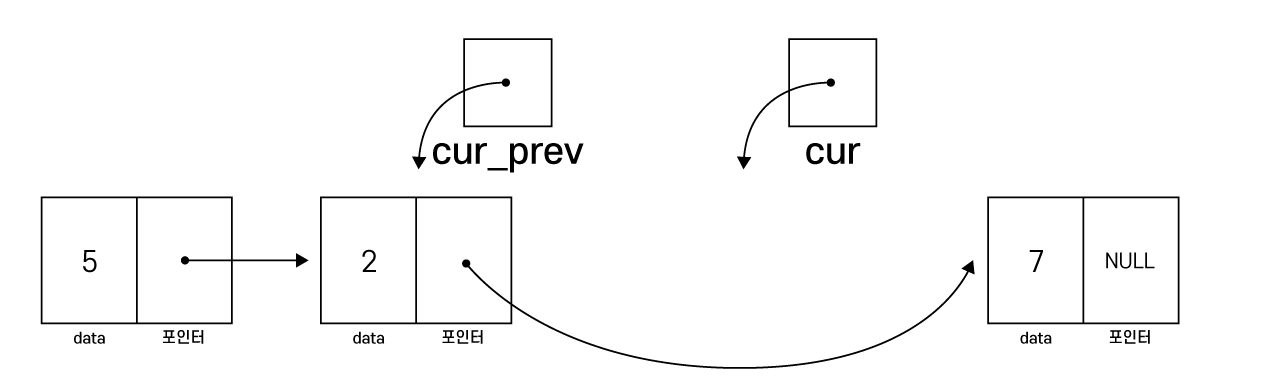
free(cur)
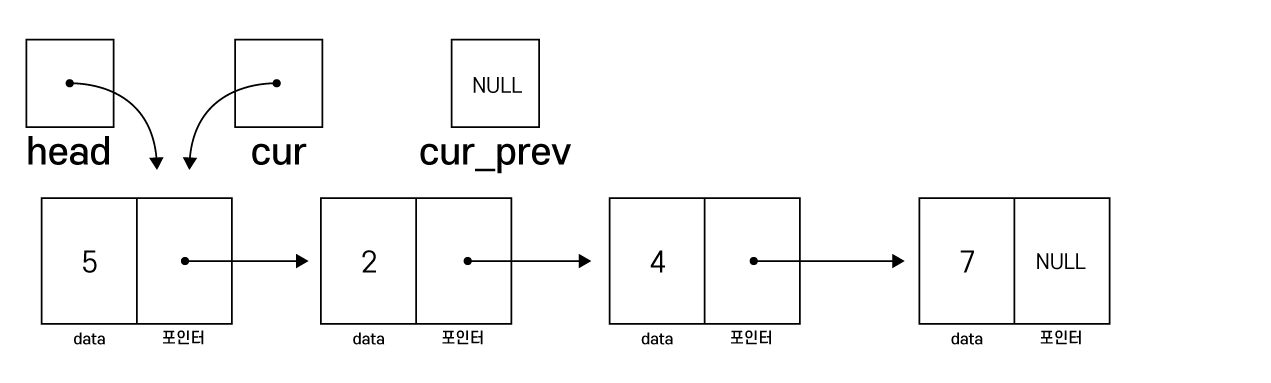
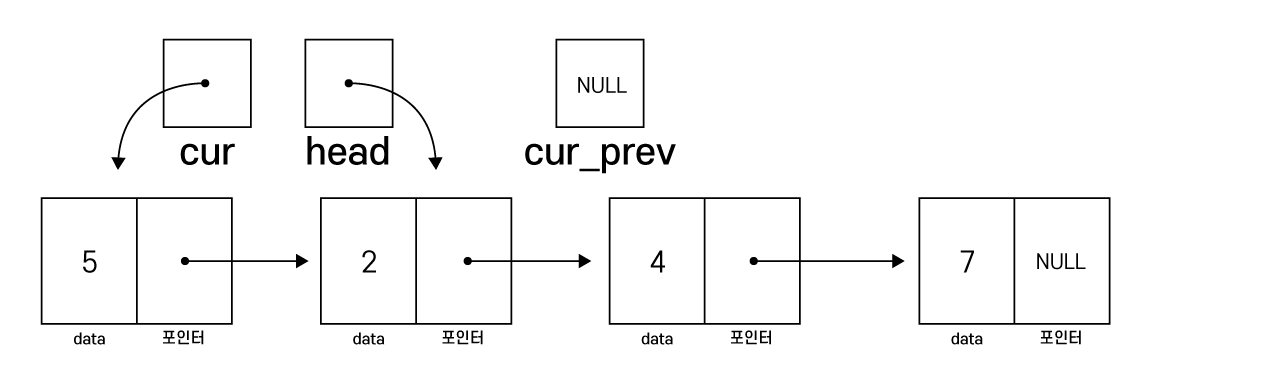
head = cur -> next
free(cur)
연결리스트를 잘 이해하고
활용하기 위해서는
머리 속에서 그림을 그려보아야 합니다.
연결리스트의 상태와 작동 방식을 머리 속에서 그려보며
코드를 작성해야 정확히 이해하고 활용할 수 있습니다.
'프로그래밍 > 자료구조 \ 알고리즘' 카테고리의 다른 글
| [자료구조 with C언어] 큐 (Queue) (0) | 2022.10.04 |
|---|---|
| [자료구조 with C언어] 스택 (Stack) (2) | 2022.10.04 |

